Comparison of AI OCR Tools: Microsoft Azure AI Document Intelligence, Google Cloud Document AI, AWS Textract and Others
Summary: The article compares six AI OCR tools: AWS Textract, Microsoft Azure Document Intelligence, Google Cloud Document AI, Rossum.ai, Super.ai and Eden.ai. It then does a deep comparison between Azure and Google, the two leading choices, in several aspects: initial setup, auto labelling data, text detection and recognition, custom labelling, auto-label accuracy, auto-label result verification, data training speed, data regions and compliance. The article concludes that Azure is the better choice.
For a project I’m working on, we are looking at different AI OCR (Optical Character Recognition) options that would allow us to import documents with various layouts and extract relevant data from them with high enough accuracy. Due to the nature of these documents and the information contained in them, it is paramount that there would be an easy way for us to train the AI models using our documents.
Without revealing exactly what types of documents we are working with, as they’re commercially sensitive, the basic premise is to:
- Import a document that might be one or more pages, the document itself may be high quality PDF, or low quality scanned documents that may or may not be skewed
- Each page may or may not contain relevant information we want to extract
- Relevant information may be structured in different ways, but usually in a tabular form (but each “line item” can either be horizontal or vertical)
In our case, a traditional OCR solution wouldn’t work as the documents often contain heaps of irrelevant data, and for the relevant data, it needs to understand the context in order to work out which data elements to extract, and how they relate to each other. Therefore, a machine learning based OCR solution that could adopt to our documents is highly desirable.
The success of the project is measured by the end results of imported data:
- How much data is detected and recognised
- How accurate the recognised data elements are
- At a minimum, 80%+ accuracy is needed in order to save time in manual data entry, and to reduce/avoid incorrect data from being checked by a human operator before entering the system
Available OCR Tools
There are a number of OCR tools available, for our project the minimum criteria are:
- AI powered solution so it can be further developed and tweaked by us for our documents
- A UI solution for data training, preferably easy to use so that non-technical team members can help with data training too
- A quick and easy way to test and verify trained models
- A solution that is compliant with the ISO standards relevant for us
- Pay by usage pricing model that’s not cost prohibitive
The tools I have discovered and considered were:
- AWS Textract
- Microsoft Azure Document Intelligence (formerly known as Azure Form Recognizer)
- Google Cloud Document AI
- Rossum.ai
- Super.ai
- Eden.ai
All six options are AI based OCR solutions. Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform (GCP) are the obvious “big three”, having their own AI models, whereas Super and Eden are aggregators that farms AI calls to providers like AWS, Azure and Google, and provides a middle layer that could potentially make the end result better (or worse). It’s unclear what model Rossum uses.
After some consideration, Rossum, Super and Eden were all taken off the table due to:
- Rossum and Super not having transparent pricing
- Eden being an API aggregator built by a small team, it’s unclear on its usefulness and longevity
With the longevity of the company and product in mind, as well as transparent pricing and commercial support, AWS, Azure and Google remain to be the leading choices.
The Big Three: AWS, Azure and Google
AWS Textract
Out of the big three, AWS is our preferred vendor due to its market leading position as a cloud service provider, as well as our existing projects already using AWS.
However, upon closer inspection, it appears Textract does not allow custom data training. Textract is provided “as-is” using Amazon’s pre-trained models, it does not allow customers like us to provide their own training data to improve on the detection and recognition of different types of documents.
AWS’ machine learning blog has published an article on “end-to-end intelligent document processing solution“ in 2020, however it does not explain in detail exactly what the capabilities are, and the solution requires a complex architecture that needs significant amount of time and effort to set up and maintain.
Azure Document Intelligence
Azure’s offering, formerly known as Form Recognizer, is an end-to-end solution that offers custom data labelling and training.
Google Cloud Document AI
Google’s offering, similar to Azure’s, is also an end-to-end solution that offers custom data labelling and training.
Comparison: Azure vs Google
With the initial assessment done, we are left with Azure and Google, so let’s dive into the deep comparison of the two platforms.
We will compare the two platforms in several aspects:
- The ease of initial set up, i.e. how quickly can we get up and running right away
- Whether a “base” pre-trained model is provided for documents with high enough accuracy so we save time in customisation and training
- The detection and recognition – how much data is accurately detected and recognised
- The custom training process, how easy is it to label custom data
- How fast or slow the training is
- The end result – provided with the same training dataset, which platform offers better results
The Initial Setup
Microsoft Azure
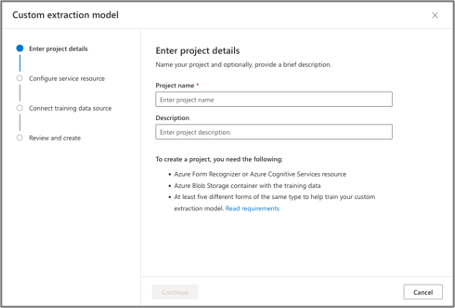
Azure’s initial set up is relatively straightforward. There is a four-step dialog window to set up the required Azure resources, etc. After which, documents can simply be uploaded for immediate consumption - labelling and training, which will be touched on in later sections.
Google Cloud
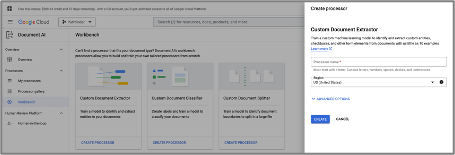
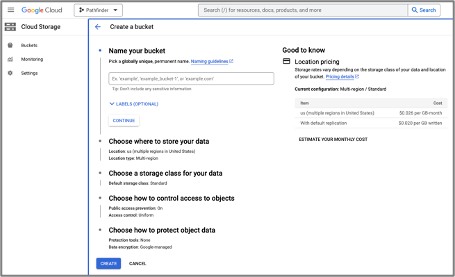
Google works slightly differently in this case. To set up a project it’s very simple, there is literally only the “Processor name” to fill out. However, it does require a separate step to set up the storage bucket required.
Also, instead of allowing files to be uploaded within the same UI like Azure, Google requires files to be uploaded to the cloud storage bucket first, then imported into Document AI.
Auto Labelling Data
Microsoft Azure
“Auto-labelling” refers to the AI OCR’s ability to do the initial labelling automatically, to save time and effort in the manual labelling work. It can be seen as the starting point of training the AI model.
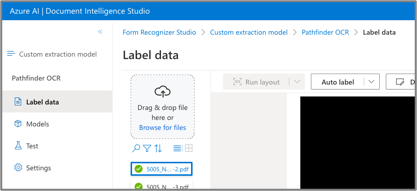
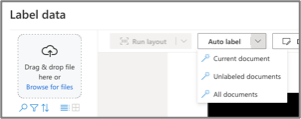
In this case, the Azure experience is significantly better. It allows files to be uploaded, then auto-labelled by “current”, “unlabelled” or “all” documents. This gives the flexibility to users (i.e. us) to choose when a document should be auto-labelled – as it does take a bit of time, sometimes if a document is not very well structured and would require more manual labelling anyway, then it’s best to skip the auto-label step.
Google Cloud
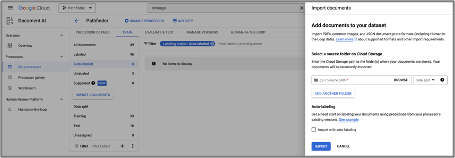
Google on the other hand, has a more cumbersome process. We first need to upload the files to the storage bucket, as mentioned before. Then, we select the path/folder of the uploaded files, and the “auto-labelling” is enabled or disabled for the entire import. Also, sometimes the import takes a long time, whereas on Azure it’s always instant.
More on the accuracy of auto-labelling later.
Text Detection and Recognition
A big part of OCR is obviously text detection and recognition. Even without training, a good OCR solution should detect and recognise clear text effortlessly.
During our initial research, we’ve found this article that compared the text recognition accuracy between AWS, Azure and Google. Their finding was that Azure and Google were comparable with a slight edge to Azure (Azure performed better on 2 out of 3 documents, and Google performed better on 1 out of 3 documents), both were way ahead of AWS in terms of accuracy.
Our own testing has somewhat mirrored their experience. We found that in general, Azure performed better in the number of detected text elements, as well as the correctness of these text.
On Azure, it’s very rare for text to be undetectable, whereas on Google, we’ve found several instances where the text is very clear, yet Google was unable to detect the text at all.
Similarly on accuracy, Azure has rarely detected clear text incorrectly, whereas on Google, a lot of times units such as x10*9/L get recognised incorrectly despite all instances appearing similar in their appearance (i.e. very clear), and sometimes dashes won’t get recognised (e.g. 10.0 - 12.50 gets recognised as 10.0 12.50).
Custom Labelling
During training, a big portion of time is spent on custom labelling, meaning we look for and assign text to our pre-defined data elements such as name and occupation - these are just fictional examples.
Overall, Azure and Google each has its strengths and weaknesses. Let’s go through them in detail.
Auto Layout
On Azure, there is a “Run layout” step that would recognise all the text elements, as well as tabular data in a given document.
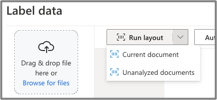
Once “run layout” is performed, all the recognised text are highlighted in yellow, giving a quick and easy overview of the usable data elements.
Google on the other hand, does not offer a similar function, therefore labelling needs to be performed with more effort, more on this later.
Schema vs Schema-less
One key difference between Azure and Google’s solutions, is that the Azure solution is schema-less whereas the Google solution is based on defined schemas.
On Azure, we can add a “field”, and then assign the field a type (string, number, etc). A field can then be renamed or re-assigned with a different type at any time.
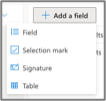
There is a special field called “table field”, we can create tabular data using this field type.
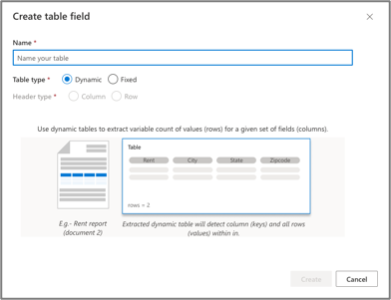
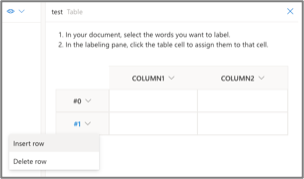
Google works very differently. Instead of adding fields on the fly, Google requires a schema (a.k.a. field definitions) to be created first. Once a field is created, and data trained, it cannot be edited or deleted.
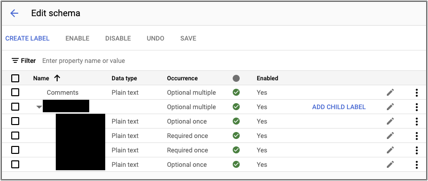
One advantage of Google’s approach is a more definitive structure of OCR’ed data. When creating a label, not only do we have to choose a type (similar to Azure), we also can choose its occurrence logic, see the screenshot below.
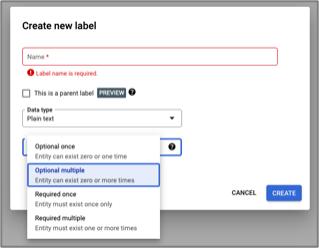
Despite this, we found that the schema-less approach on Azure offers far better versatility without being confined to a pre-defined schema, making training new revisions of models far easier.
Labelling Data
Most of the time spent on training, is the manual labelling of data elements on the documents. Azure’s approach in this case is significantly faster and more accurate, compared to Google’s.
Microsoft Azure
On Azure, because of the “run layout” step, all text elements are already detected. So labelling them as part of the test results is very simple, you click on the yellow elements to select the text you want, then click on the table cell on the right to assign them.
However, if somehow Azure detects the data incorrectly, there is no way for us to provide a correction. In this case, we could choose to either skip the cell, or simply assign the cell with the incorrect data – if more training data is provided over time then these edge cases will not have a big impact on the final accuracy of the model.
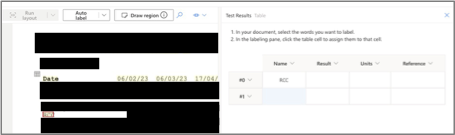
In the screenshot above, sensitive data elements are blacked out for the purpose of this blog post.
Google Cloud
On Google, this process is significantly more involved. Due to not having a “run layout”-like step, we need to draw over the text to select it, and there’s no way to tell whether Google has detected the text before using the tool, so sometimes you’ll draw over some text and get an error saying, “Cannot create labels with empty values”.
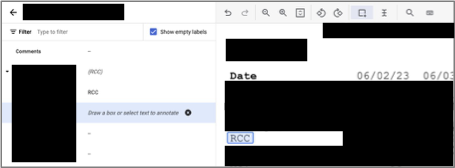
Again, in the screenshot above, sensitive data elements are blacked out for the purpose of this blog post.

And because we can’t simply click on the highlighted text already detected, like on Azure, this makes the whole process significantly longer as we have to carefully draw over the text to ensure the boundary is accurate (for training purpose), sometimes we have to zoom in and reposition the document for accurate drawing.
The schema assignment is also less intuitive compared to Azure’s. Instead of having a table to easily see tabular data, Google’s schema is more like a series of key-value pairs, making glancing at assigned data much harder, and the key-value elements are ordered alphabetically, instead of logically like on Azure, making assigning data unnatural.
The one advantage of Google’s approach though, is that when the recognised data is incorrect, we can manually override it with our own correct data. However, after using both solutions for a while, we’ve found that Google’s has a much higher error rate compared to Azure’s to begin with.
Auto-Label Accuracy
In order to assess the auto-labelling accuracy, we have trained several of our documents with varying quality and layout. We then uploaded a new document with a layout that has not been trained.
The results are very telling.
Microsoft Azure
Azure has pretty much labelled things perfectly - all the data elements were detected correctly and within the correct contexts. The second comment block is also detected correctly.
In this case, the Azure auto-label has only missed the first comment block.

The screenshot above is blurred to protect the sensitive nature of it.
Google Cloud
Google’s result unfortunately falls short of expectation.
As seen in the screenshot below, Google has missed several data elements, and incorrectly detected elements that should not be part of the result. Again, the screenshot is blurred to protect the sensitive nature of it.

This suggests two possible things about Google’s OCR solution:
- The default text recognition is poor, therefore it’s missing data elements even though they are clearly presented, in the same way as other elements
- The neural network for language models is poor, therefore it incorrectly detected text that shouldn’t be part of any result
Auto-Label Result Verification
Microsoft Azure
Once Azure’s performed the auto-labelling, it’s very easy to check the results, as seen in the blurred screenshot below, we simply look at the table to ensure the correctness. However, as mentioned before, we can only correct detected regions of text, not the content itself.

Google Cloud
On Google, it is more involved. As seen in the blurred screenshot below, it requires a lot of scrolling to find the auto-labelled data. Alternatively, we can hover over the highlighted text to look at the auto-labelled text, although in this case, the pop-up gets in the way of other data which makes it an annoyance at times.
Curiously, despite having a schema, and setting certain elements to “required once” (per schema), Google still went ahead and falsely detected multiple results per schema.
But as mentioned before, Google does offer the ability to manually correct the text content, which is a big plus.
Data Training Speed
We have found training to be significantly faster on Azure.
With about 45 documents, it takes about 30 minutes to train on Azure.
Google takes about twice as long, about an hour to train, and another several minutes to deploy the trained model. Azure does not need a separate deployment step.
Interestingly, on Google, training a model requires having enough test data. So documents need to be split into training and test groups. It is unclear whether the test data is used for actual training.
There is also a required number of labelled elements (10 minimum, 50 recommended) before a model can be trained. Azure has no such limitations.

Data Regions and Compliance
While both Azure and Google are compliant to many standards (ISO, GDPR, etc), Google’s Document AI can only be hosted out of their US or EU regions. Whereas Azure has no such limitation and can be hosted in any of their available regions.
This has a side effect on the performance of UI operations. Azure is very quick and snappy due to it being deployed in our local AU region, whereas Google due to it being deployed in the US region, is a little slow every time you open and close a document for example.
Conclusion
With the in-depth analysis done, it is no surprise that in the end we went with Microsoft Azure’s Document Intelligence for our AI OCR needs. I hope these findings are useful to other people too.
Enjoy what you are reading? Sign up for a better experience on Persumi.