Coding and Learning Should Never Stop, Open Sourcing is Caring
I’ve had a productive coding weekend, and so I decided to share my experience. Now, many developers choose to treat their career as a series of 9-5 jobs, but if you’re reading this, I assume you’re like the rest of us who love continuous learning and self improvement.
Preface
About a year ago I started learning Elixir. So as part of the learning experience, I wrote two matching learning related libraries: Stemmer and Simple Bayes. It was a great, really enjoyable experience and I learnt a lot about the concepts of word stemming, naive Bayes classification and of course, functional programming.
These topics have been interesting to learn about, but until one gets to use them on a daily basis for a while, key concepts are less likely to convert from short term memory to long term memory. Given my day job is not about writing Elixir (yet), I needed to find other ways to keep my skill-level up and to continue exploring new things.
So about a month ago, I picked up a project I started a year ago but gave up shortly after: Crawler. At the time GenStage was just announced and I was interested in incorporating it into my project as I thought it’d be a great fit. But due to varies reasons - mostly not having a firm grasp of the GenStage concept and implementation, as well as taking on a CTO role at a startup, I couldn’t find enough time and patience to make it work so I had to let it go.
Until now.
Crawler, on Steroids
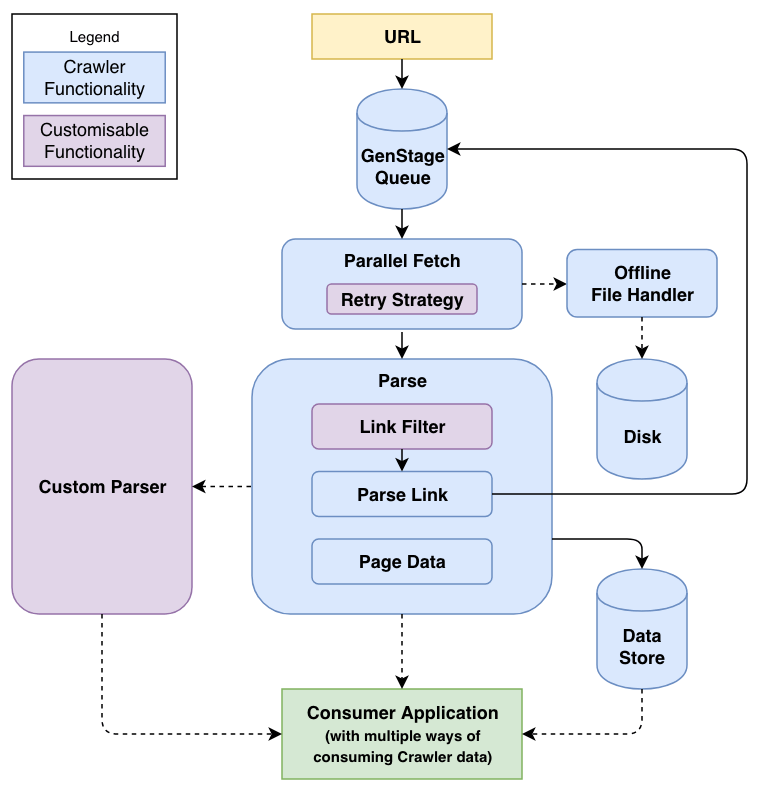
I’d realised that the way I was trying to incorporate GenStage into my project was never going to work. Not because of GenStage itself, but because of the way I approached learning it. At the time I was so eager to make use of GenStage, and coming off the back of my good streak of releasing the aforementioned machine learning libraries, I thought I could take shortcuts and things would all work out perfectly.
No.
So I licked the wounds, learnt my mistakes and changed tactics. This time, I scoped out and encapsulated my learnings (just as one would in designing a software system), and eventually I came up with another library - OPQ: One Pooled Queue.
OPQ: One Pooled Queue
I knew Crawler could technically work without any queueing system, or GenStage. So I kept on building Crawler, until I felt productive in writing Elixir again, and touched enough areas and concepts that I knew exactly what I needed from GenStage.
And luckily for me too, GenStage over the past year has matured and more importantly, has better documentation with more code examples. Upon closer investigation of the code examples, I found that their GenEvent and RateLimiter examples were almost exactly what I needed. It was an epiphany moment for me after reading and understanding these examples, all of a sudden I “get it”.
If you take a look at the source code of OPQ you’ll notice that the heavy lifting logic was mostly inspired (or even copy-pasted) from those examples.
Open Sourcing is Contributing and Caring
Up until this point, as far as writing open source Elixir code goes, it had mostly been me writing my own code for my own projects. But open sourcing is much more than just writing one’s own code and publishing them on Github.
If you’ve followed my work you’ll know that I’m a big fan of contributing to other projects, some of which are well-known ones like Rails and Slim.
It just so happens, that over the weekend I ran into situations where I needed to contribute to other Elixir projects - and spoiler alert: one of which is Elixir itself.
ElixirRetry
One of the features I set out to add to Crawler, was to allow failed crawls to retry before giving up. Naturally, the first thing I did was to try find an existing package to support the retry functionality.
After some googling and digging into some source code, I’ve found and settled on ElixirRetry - a neat library that was cleverly built.
Soon I found out that since its last release, it offered both retry/2 and retry/3, the latter of which was to support an extra argument that specifies which exceptions to allow as part of the retry flow. It was a great addition, but it doesn’t effect me as Crawler doesn’t need it.
As a developer who cares deeply about code quality and clarity, I immediately thought about how the interfaces for retry/2 and retry/3 could be improved, by simply combining them and making the extra argument in retry/3 an option.
So I did, and issued a pull request here: https://github.com/safwank/ElixirRetry/pull/12 You’ll notice that I’ve also made some improvements to the test suite while I was at it. ;)
Elixir Typespec
One issue I ran into while building Crawler, was the static analysis via Dialyzer - some code that actually ran and passed tests functionally, failed the type checking.
As someone who isn’t as experienced in Elixir, I first opened an issue and phrased it more as a question seeking validity of the issue. I then jumped on Elixir’s Slack group and asked people in the group about this issue.
Fortunately, Ben Wilson immediately came to aid by verifying my issue and validating my suspicion of it being an issue in Elixir’s typespec documentation.
And so, a pull request was created and approved shortly after.
Sharing is Caring
The bulk of Crawler as well as the entirety of OPQ were built in the past month or so. I hope some people will benefit from having these libraries around. And, I hope people also enjoyed me sharing my experience, and perhaps be inspired to start sharing more too.
I will leave you all with a Chinese saying: 滴水石穿. The literal translation is “dripping water penetrates the stone”, and what it means is “constant perseverance yields success“.
Enjoy what you are reading? Sign up for a better experience on Persumi.